【论文笔记】Recurrent neural network based language model
提出了一种新的基于递归神经网络的语言模型(RNN LM),并将其应用于语音识别。结果表明,与最先进的后退语言模型相比,使用几个RNN LMs的混合物可以减少大约50%的困惑。语音识别实验显示,在《华尔街日报》任务上,与在相同数据量上训练的模型相比,单词错误率降低了18%左右,在更难的NIST RT05任务上,错误率降低了5%左右,即使是在backoff模型比RNN LM训练的数据多得多的情况下。我们提供了充分的经验证据,表明连接主义语言模型优于标准的n-gram技术,除了它们的高计算(训练)复杂性。
Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]//Interspeech. 2010, 2(3): 1045-1048.
模型设计
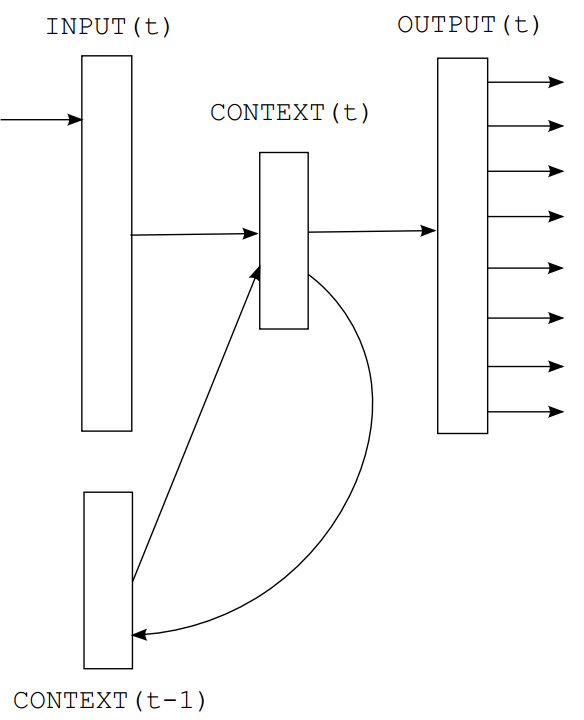
本文提出了简单的递归神经网络,称为Elman网络架构: $$ x(t)=w(t)+s(t-1) $$
$$ s_j(t)=f(\sum_ix_i(t)u_{ji}) $$
$$ y_k(t)=g(\sum_js_j(t)v_{kj}) $$
其中, $$ f(z)=\frac{1}{1+e^{-z}} $$
$$ g(z_m)=\frac{e^{z_m}}{\sum_k e^{z_k}} $$
训练分为几个epoch进行。所有训练数据都是顺序呈现的,权重初始化为小值(随机高斯噪声,平均值为零,方差为0.1)。起始学习率为$\alpha=0.1$。每个epoch后,对网络进行验证数据测试,如果验证数据的对数似然增加,则继续进行,否则$\alpha$减半,如果仍然没有改善,训练结束。通常训练10~20epoch后收敛。
- 动态训练:运行测试时仍然更新参数
请注意,统计语言建模中的训练阶段和测试阶段通常是不同的,因为模型不会在处理测试数据时得到更新。所以,如果一个新的人名在测试集中反复出现,即使它是由已知单词组成的,它也会反复得到一个非常小的概率。
可以假设,这种长期记忆不应该存在于上下文单元的激活中(因为这些单元变化非常快),而应该存在于突触本身——即使在测试阶段,神经网络也应该继续训练。我们把这样的模型称为动态模型。对于动态模型,我们使用固定学习率α = 0.1。而在训练阶段,所有的数据都是在epoch中多次呈现给网络,而动态模型在处理测试数据时只更新一次。这当然不是最优解决方案,但正如我们将看到的,它足以获得相对于静态模型的大的困惑减少。注意,这种修改与backoff模型的缓存技术非常相似,不同之处在于神经网络是在连续空间中学习的,所以如果’ dog ‘和’ cat ‘是相关的,那么在测试数据中频繁出现’ dog ‘也会触发’ cat ‘的概率增加。
优化
为了提高性能,我们将出现频率低于阈值(在训练文本中)的所有单词合并到一个特殊的稀有标记中。单词概率计算为: $$ P(w_i(t+1)|w(t),s(t-1))= \begin{aligned} \left\{ \begin{aligned} \frac{y_{rare}(t)}{C_{rare}},若w_i(t+1)是rare的\\ y_i(t),其他\\ \end{aligned} \right. \end{aligned} $$
实验和结论
RNN 相比于 Bengio 中的 FNN 的主要优势在于没有指定固定的语境,而是使用隐藏层的状态概括之前所有的语境信息。优点包括需要指定的超参数数量少。实验发现,最朴素的RNN LM模型的效果远好于(各种) n-gram 。